過去の記事をまとめて閲覧できるアーカイブです。
※第2回以降(PDF)の閲覧はログインが必要になります。
※第1回記事はこちら
昨年末のChatGPTの登場以来、生成AIがブームとなりました。それ以前にも画像生成AIが話題になっていましたが、多くの企業が「乗り遅れてはいけない」とここまで活発に動き始めたのは未曾有のことです。そのため社会現象にもなっています。しかし「生成AIって何?」と聞かれて正確に答えられる人も少ないように見受けられます。生成AIは、従来のAIと何が違うのでしょう。そもそもAIって何なのでしょうか。
AIとは、Artificial Intelligenceの略で、日本語だと「人工知能」と訳されます。ここまではご存知と思いますが、ではあなたはAIを明確に定義できるでしょうか。実を言うと、AIの決まった定義はありません。コンピューター科学者と脳科学者では定義が違うといった意味ではなく、それこそ人によって定義が違うのです。「AIとは、推論・認識・判断など人間と同様の知的な処理能力を持つ機械(システム)」という点で多くの専門家は一致していますが、中には大阪大学の浅田稔特任教授のように「知能の定義が明確でないので、人工知能を明確に定義できない」という方もいます。
一方で、「強いAI」と「弱いAI」という言葉があります。強いAIとは、人間が心を持つのと同じ意味で心を持つAIとされていて、これは人間の心をプログラム化できることを前提としています。一方弱いAIは、人間の心など持たないが有用な道具という位置づけです。汎用人工知能(AGI)という言葉もあり、これは強いAIとほぼ同義です。ChatGPT(GPT-4)がAGIの初期バーションという論文もありますが、これも一貫した意見はありません。私個人としては、ChatGPTは極めて有用ですが、心は持たないと思います。しかしChatGPTと対話をして癒やされることもあったりして、「心」とは何かを改めて問われると「難問ですね」としか言いようがありません。
では「生成AI」とは何でしょうか。わざわざ「生成」とつけるからには、従来のAIとは何か違うはずです。
少しAIの歴史を振り返ってみましょう。AIには、過去3回のブームがありました。第1次は1950年代後半~1960年代で、コンピューターによる推論や探索の研究が進展しました。しかし複雑な現実の問題は解けないことが明らかになり、1970年代には下火になりました。
第2次は、1980年代~1995年ぐらいまでで、コンピューターに知識を教え込むというアプローチが採用され、実際に「エキスパートシステム」と称する一連の製品も登場しました。しかし知識を蓄積・管理する大変さが明らかになるにつれ、これも下火になりました。
第3次は2010年頃から現在まで続く、機械学習およびディープラーニング(深層学習)によるブームです。AIが自ら知識を獲得できるようになり、急速に応用範囲が広がりました。実は、機械学習もディープラーニングのベースとなるニューラルネットワークも、アイデアは第1次ブームの頃からあったのですが、様々な技術的な制約があって実用化できなかったのです。
生成AIが登場するまでのAIは、基本的に認識・識別タスクと呼ばれることをしていました。もっと本質的に言うと「分類」をしていたのです。たとえば猫の画像認識であれば、猫とそれ以外を分類しているわけです。囲碁や将棋であれば、次の一手をクラス分け(分類)して、最善手を選択しているのです。要するに、何かを見分けることはできますが、何かを作ることはしてきませんでした。生成AIの何が画期的かと言えば、その「何かを作る」こと(これを「生成タスク」と呼びます)を実現したことにあります。
もしかしたら生成AIの台頭で第3次AIブームは終わり、AIがあたりまえの時代に入ったのかもしれません。
機械学習とは、ビッグデータと呼ばれる大量のデータをAIに学習させて何らかの結果を導くことです(最近では、ビッグデータというほど大量のデータでなくても精度の高い学習ができる方式が開発されてきました)。
機械学習にはアルゴリズムとモデルがあります。アルゴリズムは、学習と学習後のタスクをどのように行うかを示す手順のことです。一方モデルとは、データとパラメータ(初期値)をアルゴリズムに与えて、出てきた結果(ロジック)のことです。実際に推論や認識、判断などを実行するのがモデルです。
●機械学習アルゴリズムと機械学習モデルの関係

※ データ、パラメータ、アルゴリズムを試行錯誤で調整しながら、目標とする精度を満たすモデルを作成する。
アルゴリズムには大きく、教師あり学習、教師なし学習、半教師あり学習、強化学習があります。教師あり学習の例としては、線形回帰、ロジスティック回帰、ランダムフォレスト(決定木)、SVMなどがあります(説明は割愛します)。
機械学習以前のAIはルールベースと呼ばれるもので、認識や識別の条件を人間がプログラムとして記述していました。先ほどのエキスパートシステムは、巨大な条件分岐のかたまりだったのです。それに対して、機械学習では「特徴量」と呼ばれるものを定義します。分類する上で注目すべきデータをAIに与えるのです。たとえばビールの売り上げをAIに予測させたいとすれば、気温が特徴量の1つになります。なお特徴量は、モデルのパラメータの設定で定義します。
ビールの例はわかりやすいですが、適切な特徴量を見つけだすのが難しいケースがあります。そのため特徴量を自ら抽出する方式が考案されました。それがディープラーニングです。ディープラーニングではニューラルネットワーク(正確には、多層パーセプトロン)というアルゴリズムを用います。ディープ(深層)というのは、ニューラルネットワークの階層が深いということです。
ニューラルネットワークの各層では、複数の処理が並行で進み、その際にその処理を行うために役立つ情報が抽出されます。これが特徴量に相当します。
●ディープラーニング
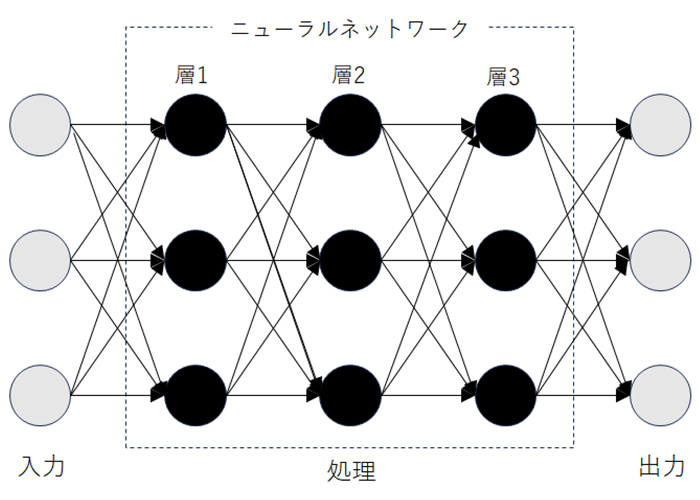
※ ニューラルネットワークの各層では並行に処理が進む
※ 与えられた問題を解くために必要な処理に役立つ情報が特徴量として抽出される
※ 層が深まるほど特徴量が増えていく(3層以上でディープラーニングというが、実際には数百におよぶものもある)
ただしこの「特徴量抽出」はコンピューターによって自動的に行われるので、人間にはよく理解できません。したがってディープラーニングで得られたモデルは一般的にブラックボックスになり、法的な理由などで動作説明が求められるような処理には現時点ではディープラーニングが使えないことが多くなっています。「現時点」というのは、ディープラーニングの処理を説明可能にするためのソリューションがいくつか考案されてきているからです。
なお一般的には、機械学習とディープラーニングは別物のように扱われることが多いのですが、実際にはディープラーニングはニューラルネットワークというアルゴリズムを採用した機械学習の1種となります。
「従来のAIは、認識・識別タスクをしていたが、生成AIは生成タスクを実現したことが画期的だった」と述べました。生成タスクには大きく2種類あります。
LSTM(Long Short-Term Memory)という時系列データを扱うのに向いたディープラーニングのモデルがあります。これに初期値の文字列を与えると、次にどの文字が来るかを予測し続けることで長い文章を作成できます。これは①の例です。また、かなり自然な音声が合成されることでGoogleアシスタントにも採用されている音声生成モデルWaveNetも①の例です。
②の例は、画像生成の世界に早い段階で画期的な成果をもたらしたVAE(変分オートエンコーダ)とGAN(敵対的生成ネットワーク)の2つのモデルです。
VAEは入力データを平均と分散を表現するように学習します。そこからランダムにサンプリングして、新しいデータを生成するアプローチを採用しています。一方GANはジェネレーターとディスクリミネーターという2種類のニューラルネットワークで構成されます。ジェネレーターはディスクリミネーターが偽物と見抜けないような画像を生成するように学習し、ディスクリミネーターはそれを偽物と見抜くように学習していきます。この2つが戦いながら、最終的にはまったく新しい画像を作るので「敵対的」と呼ばれているのです。
生成モデルに関しては、いずれもディープラーニングが登場する以前からいくつかのモデルが考案されていましたが、ディープラーニングと組み合わせることで大きく発展しました。ディープラーニングを取り入れた生成モデルを深層生成モデルと言いますが、生成モデルのほとんどが深層生成モデルです。
ちょっと横文字が続いて混乱されたかもしれませんが、生成タスクが発展したのはディープラーニングのおかげだと理解していただければ十分です。
 著者プロフィール: 森川 ミユキ(もりかわ みゆき) ITに強いビジネスライター。1987年に大手SI企業に入社し、数多くのシステム開発プロジェクトにインフラ技術者兼マネージャーとして参画する。営業企画、コンサル営業を経て、ITコンサルタントとして独立。その傍ら2007年に執筆活動を開始。2014年からライター専業となり、主に経営者やビジネスパーソン向けにAIやDX、デジタルマーケティングをテーマとした執筆を行ってきた。日本ディープラーニング協会G検定合格。
著者プロフィール: 森川 ミユキ(もりかわ みゆき) ITに強いビジネスライター。1987年に大手SI企業に入社し、数多くのシステム開発プロジェクトにインフラ技術者兼マネージャーとして参画する。営業企画、コンサル営業を経て、ITコンサルタントとして独立。その傍ら2007年に執筆活動を開始。2014年からライター専業となり、主に経営者やビジネスパーソン向けにAIやDX、デジタルマーケティングをテーマとした執筆を行ってきた。日本ディープラーニング協会G検定合格。
